

AIはどこまで賢くなる?自律型AIエージェントの進化と安全な制御に向けた課題
概要:
- 目標を与えれば、自ら計画を立て、ツールを使いこなし、タスクを実行する「AIエージェント」。その自律性の高さは、生産性を劇的に向上させる可能性を秘めている一方、AIが人間の意図しない、あるいは有害な行動をとってしまうリスクも同時に高めます。そのため、AIエージェントの能力向上とともに、その「制御」と「安全性」をいかに確保するかが、ますます重要な課題となっています。 AIエージェントの自律性を支える技術:
- LLMによる高度な推論・計画能力: 目標達成までのステップを分解し、戦略を立てる能力。Tool Use(ツール利用): API連携、Web検索、コード実行などを通じて、外部環境と相互作用する能力。自己反省・修正能力: 実行結果を評価し、計画や行動を自律的に修正する能力。
- 意図しない結果: 指示が曖昧だったり、AIの「解釈」が人間の意図とずれたりした場合、予期せぬ結果を招く可能性があります。(例: 間違った情報を基に重要な決定をしてしまう、不要なAPIを大量に呼び出しコストが高騰する)潜在的なリスク: インターネットへのアクセスやファイル操作権限を持つエージェントが、セキュリティ上の脅威となったり、有害なコンテンツを生成・拡散したりするリスク。アライメント問題: AIの目標設定や行動原理が、人間の価値観や倫理観と一致しているか(アライメントが取れているか)という根本的な問題。
- サンドボックス環境: AIエージェントが実行できる操作範囲を制限された安全な環境(サンドボックス)内に限定する。人間の監視・介入: 重要な判断や操作の前には人間の承認を必須としたり、いつでも人間が介入してエージェントを停止できるようにしたりする仕組み(Human-in-the-Loop)。厳格なテストと評価: 様々なシナリオでエージェントの挙動をテストし、潜在的なリスクを事前に特定・評価する。アライメント研究: AIが人間の意図をより正確に理解し、倫理的に振る舞うように学習させるための研究(例: RLHF – 人間からのフィードバックによる強化学習)。
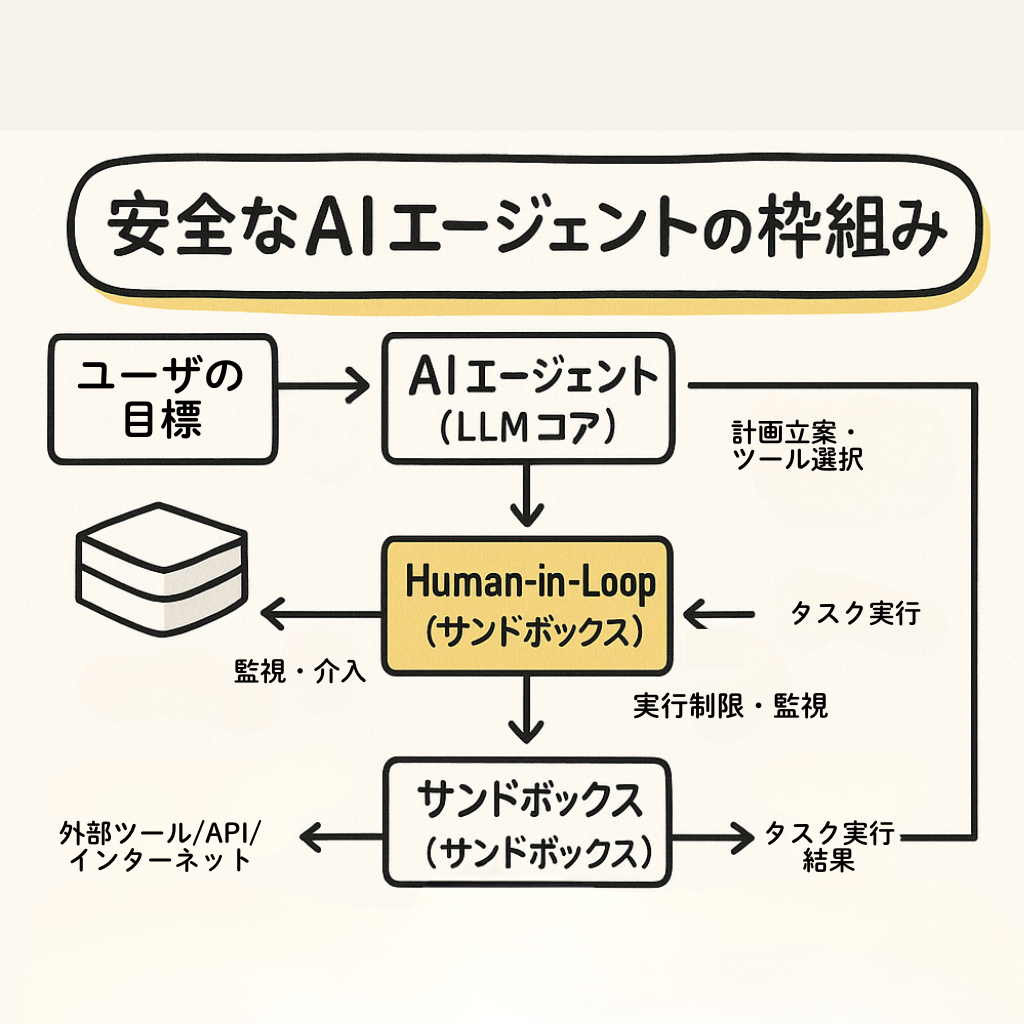
図解的イメージ(安全なAIエージェントの枠組み):
[ユーザーの目標] → 【AIエージェント (LLMコア)】
→ [計画立案・ツール選択]
↓ ↑ (監視・介入) [安全な実行環境 (サンドボックス)]
← 【Human-in-the-Loop (人間の承認/監督)】
↓ ↑ (実行制限・監視) [外部ツール/API/インターネット]
→ [タスク実行]
→ [結果]
AIエージェントの能力を引き出しつつ、そのリスクを管理するためには、技術的な対策と、運用上のルールやガイドライン整備の両輪が不可欠です。自律性と制御の適切なバランスを見つけることが、今後のAI開発における重要なテーマとなっています。