

AI界激震!Metaが超高性能オープンソースLLM「Llama 3」を発表!何がすごい?
概要:
先週最大のニュースは、間違いなくMeta社による次世代オープンソース大規模言語モデル(LLM)「Llama 3」の発表でしょう。今回リリースされたのは、**8B(80億パラメータ)と70B(700億パラメータ)**の2つのサイズの事前学習済みモデルおよび指示チューニング済みモデルです。
- パラメータとは? LLMの性能や知識量を左右する内部的な調整値のこと。一般に、パラメータ数が多いほど高性能になる傾向がありますが、計算コストも増大します。
- 指示チューニング (Instruction Tuning) とは? 事前学習済みのLLMに、人間からの指示(例:「~を要約して」「~について説明して」)に従うように追加学習させること。これにより、対話型AIとしてより使いやすくなります。
Llama 3の驚くべき点:
- 最高レベルの性能: Metaによると、今回リリースされたLlama 3の8Bモデルと70Bモデルは、同等サイズの他のオープンソースモデルはもちろん、一部の主要なプロプライエタリ(非公開)モデルをも上回る性能を、様々な業界標準ベンチマーク(MMLU, GPQA, HumanEvalなど)で達成したと報告されています。特に70Bモデルは、推論能力やコード生成能力で目覚ましい結果を示しています。
- ベンチマークとは? LLMの様々な能力(知識、推論、数学、コーディングなど)を測定するための標準的なテストのこと。性能比較の指標となります。
- 巨大な学習データ: Llama 3は、Llama 2の7倍以上となる15兆トークン以上(!)という、これまでにない規模の高品質な公開データセットで事前学習されています。これが高性能の基盤となっていると考えられます。
- 改善された安全性: 安全性にも力が入れられており、「Llama Guard 2」や「CyberSec Eval 2」といった新しい安全評価ツールや、「Code Shield」という推論時フィルタリング技術なども導入されています。
- オープンソースとしての公開: これだけの高性能モデルが、研究者や開発者が比較的自由に利用できるオープンソースライセンス(Llama 3 Community License Agreement)で公開されたインパクトは非常に大きいです。
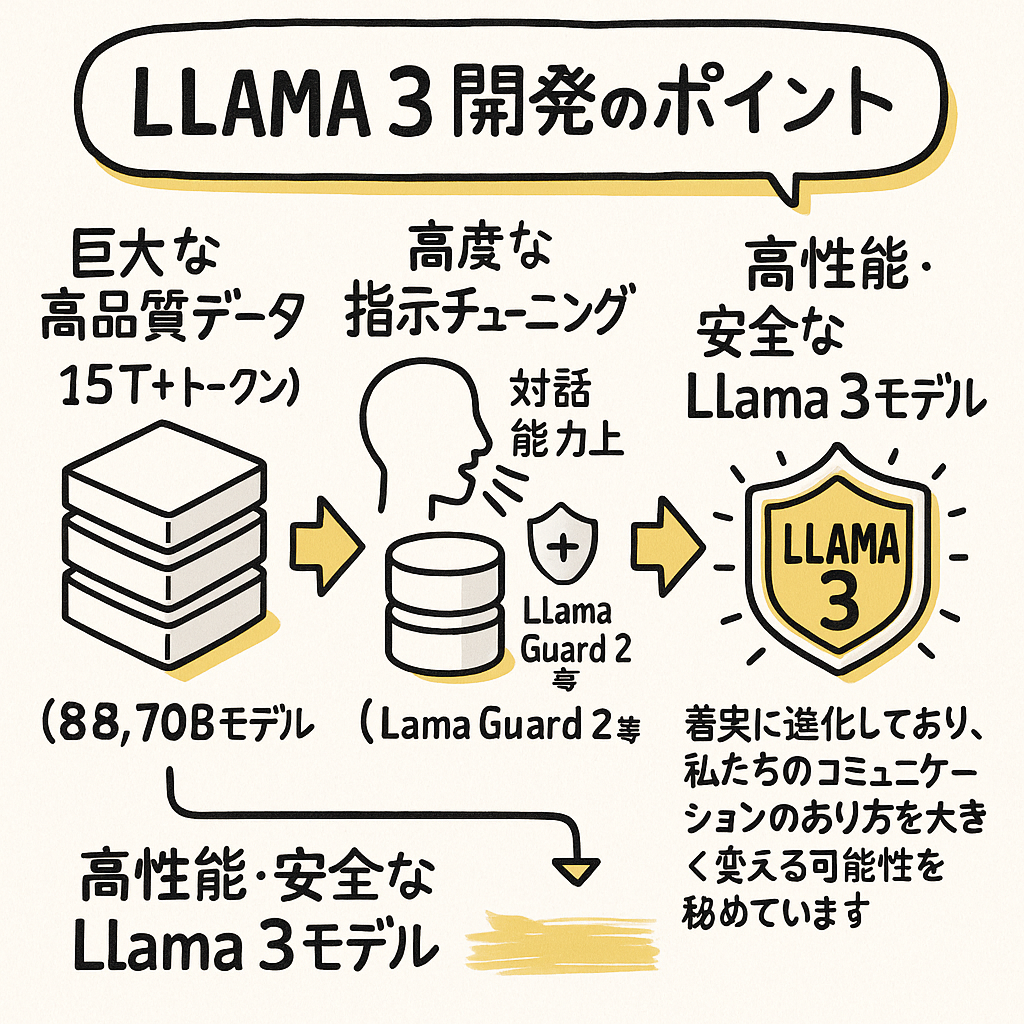
図解的イメージ(Llama 3開発のポイント): [
巨大な高品質データ (15T+ トークン)]
→ [大規模な事前学習 (8B, 70Bモデル)] → [高度な指示チューニング (対話能力向上)] + [安全性強化 (Llama Guard 2等)]
→ 【高性能・安全なLlama 3モデル】
着実に進化しており、私たちのコミュニケーションのあり方を大きく変える可能性を秘めています。