


見て、聞いて、話せるAIへ!マルチモーダルAIが実現する次世代インターフェース
AIがテキストだけでなく、画像、音声、動画といった複数の情報形式(モダリティ)を統合的に理解し、生成する「マルチモーダルAI」の進化が止まりません。先週も、いくつかの興味深い研究発表や技術デモンストレーションがありました。
注目すべき進展:
- 画像からの複雑な指示理解: スマートフォンで部屋の写真を撮り、「この写真に写っている赤いクッションと同じようなデザインで、青色のものをオンラインストアで探して」といった、画像とテキストを組み合わせた複雑な指示をAIが正確に理解し、タスクを実行するデモが公開されました。これは、視覚情報と言語情報を高度に連携させる能力を示しています。
- 動画生成・編集能力の向上: 短いテキスト指示から、より長く、より一貫性のある高品質な動画を生成する技術や、既存の動画に対して「この部分の背景を変えて」「この人物の服装の色を変えて」といった編集指示を自然言語で行える技術が向上しています。クリエイティブ産業での活用が期待されます。
- リアルタイム対話: ユーザーの声色や表情といった非言語情報も理解し、より人間らしい自然なタイミングやトーンで応答するマルチモーダル対話システムのデモが登場しました。AIアシスタントやバーチャルヒューマンの表現力が向上しそうです。
技術的背景: これらの進展の背景には、大規模言語モデル(LLM)と、画像認識や音声認識などの他のAI技術を効果的に統合するアーキテクチャの研究があります。例えば、「Vision Transformer (ViT)」のような画像認識モデルと言語モデルを接続したり、異なるモダリティの情報を共通の表現空間(埋め込み空間)で扱ったりする技術が用いられています。
図解的イメージ(マルチモーダル処理):
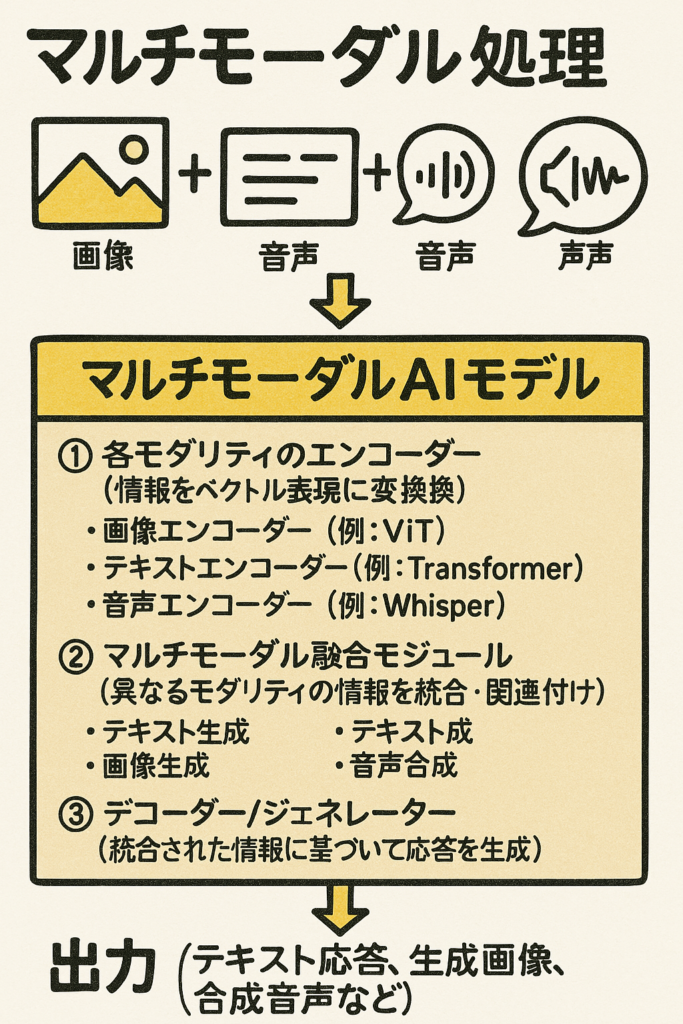
[入力] (画像データ + テキスト指示 + 音声) ↓ 【マルチモーダルAIモデル】 ① 各モダリティのエンコーダー (情報をベクトル表現に変換) – 画像エンコーダー (例: ViT) – テキストエンコーダー (例: Transformer) – 音声エンコーダー (例: Whisper) ② マルチモーダル融合モジュール (異なるモダリティの情報を統合・関連付け) ③ デコーダー/ジェネレーター (統合された情報に基づいて応答を生成) – テキスト生成 – 画像生成 – 音声合成 ↓ [出力] (テキスト応答、生成画像、合成音声など)
今後の展望: マルチモーダルAIは、より直感的で豊かな人間とAIのインタラクションを実現する鍵となります。スマートグラスのようなウェアラブルデバイスとの連携や、教育、医療、エンターテイメントなど、様々な分野への応用が期待されます。とによる制御の難しさ、予期せぬ行動のリスク、コスト(多くのAPIコールや計算資源を消費する可能性)などが課題として挙げられます。しかし、AIエージェントは、AIの能力を飛躍的に高める可能性を秘めた、非常に注目すべき技術分野です。