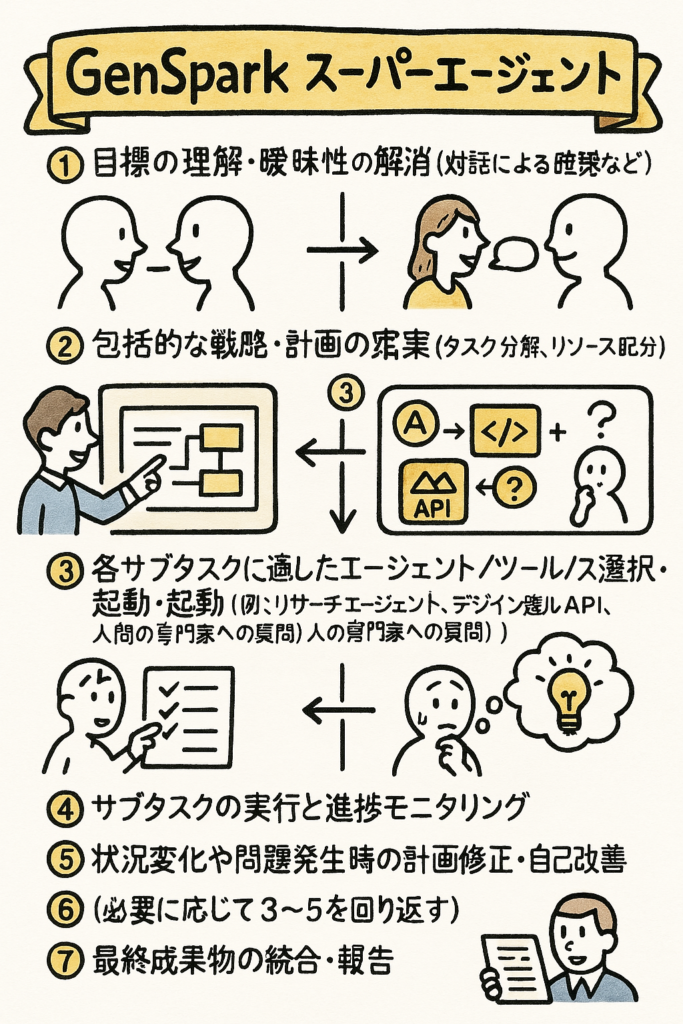
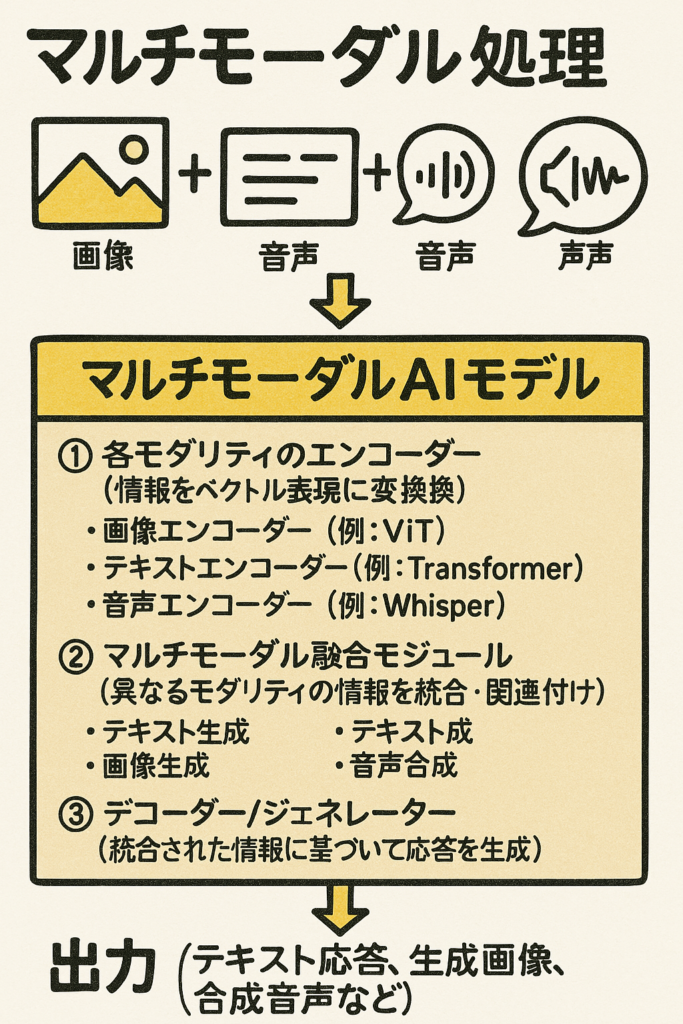
🤖 最新AIニュース総覧
2025年6月29日更新



🌍 AIと国際展開・投資

📊 AI業界の動向
40%
経営者の生成AI毎日利用率
13種
セブン-イレブンが導入するLLMモデル数
8,000人
セブン-イレブンの全社員数
3社
日本進出を発表した海外AI企業数